I maintain a bespoke learning management platform application that I built for my team to track all kinds of student data. This week, I finally decided I wanted to tackle the slowest request in the entire application - students by cohort. I knew it would be a challenge to take all of the individual ORM statements I have written over the past 2 years and consolidate them into a speedier process. I was planning on spending about a week to analyze, tinker, refine and deploy a solution.
GenAI beat me to it.
It stole all that time and allowed me to do the entire process in about 10 minutes. Here's the tale about how it was able to steal my work from me.
Data Context
First, I learned that this infernal tool can ingest the DBML for my entire database as context and understand how the structure and relationships work. Here's a screenshot of my database. It's certainly not a large database, but 38 tables can challenge the most structured mind when trying to get data that spans 10 of them, and also requires conditions, grouping, and aggregate functions.
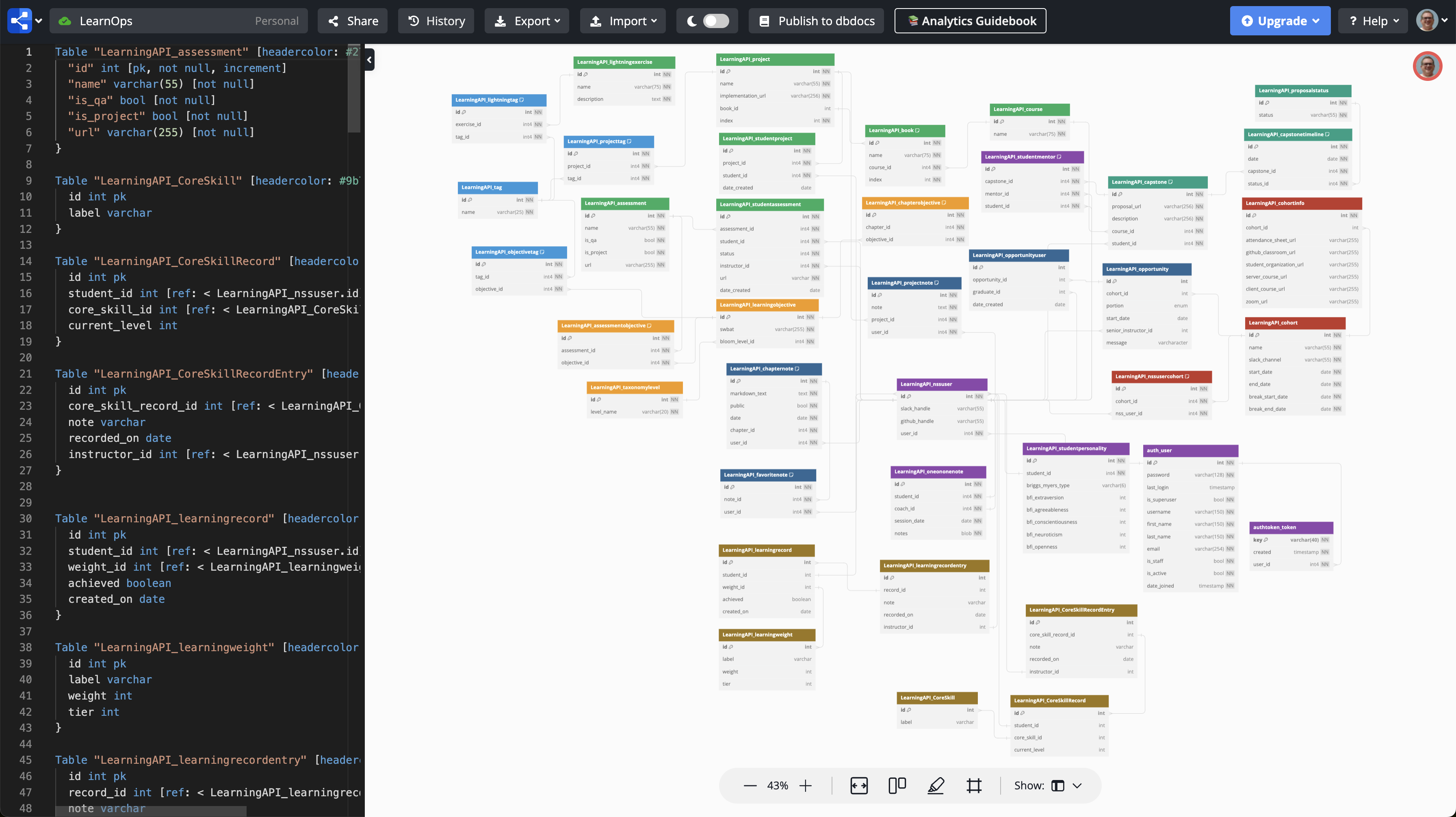
Since I know that it can parse DBML and generate high quality SQL statement from it, I decided to give this bugaboo the opportunity to fail. There was no chance that it could work at this level of complexity. I was sure of it.
I am providing the DBML for my API project below. I need you to take on the role of a business analyst and an expert SQL developer to help me generate SQL statements for new features for the project, and optimizing existing queries.
```dmbl
{ all my DBML here }
```
It was over-confident right from the get go. I couldn't wait to rub its smug face in how much I could do as a human that it couldn't.
Based on your DBML for the API project, I will help generate SQL statements for new features you might be considering and making existing queries more efficient.
Yeah, we'll see.
Slow Django Serialization
Again, my most egregious crime in this app is the slow build-up of more and more data being added to the information to be sent as JSON about the students in a cohort.
At first, it was just what project was being worked on. Then it was if an assessment was being worked on. Then weighted learning scores, assessment status, capstone submission, capstone submission statues, on and on and on. Finally, after all those additions, the HTTP request was taking over 2 full seconds to complete - unacceptable.
Now it was time to show GenAI how much it sucks and it will never replace humans. It's only for losers who don't know how to code in the first place. I copy-pastad my entire Django model, which has 6 methods on it used by the Serializer for producing a response. I asked it to produce a single SQL statment that would replace all of the separate ORM statements.
Below is an abbreviated version of the model. An experienced developer will immediately notice how much of a performance hit these will incur when run separately when used by a serializer build the JSON.
Time to break GenAI. Below is my prompt for ChatGPT, and I knew that I would get complete garbage as a response, and with further prompting, I might get something that could save me a little bit of time.
The Big Prompt
Here is a Django model based on the DBML above. Currently there are 6 methods - book, assessment_status, proposals, score, assessment_overview, and current_cohort - that are all used by a serializer to produce a JSON response with all of this information about a student. Because all of these execute separately, the operation can take over 2 seconds to complete. I want all of these combined into either a single Django ORM statement, or the full SQL in order to create a database function.
class NssUser(models.Model):
"""Model for NSS-specific user information beyond Django user"""
@property
def book(self):
student_project = StudentProject.objects.filter(student=self).last()
assigned_cohort = self.assigned_cohorts.order_by("-id").last()
if student_project is None:
cohort_course = CohortCourse.objects.get(cohort=assigned_cohort.cohort, index=0)
project = Project.objects.get(
book__course=cohort_course.course, book__index=0, index=0)
...
@property
def assessment_status(self):
try:
student_assessment = self.assessments.last()
if student_assessment.assessment.book.id != self.book["id"]:
return 0
status = student_assessment.status.status
...
@property
def proposals(self):
try:
lastest_status = CapstoneTimeline.objects.filter(capstone=OuterRef("pk")).order_by("-pk")
proposals = self.capstones.annotate(
course_name=F("course__name"),
current_status_id=Subquery(
lastest_status.values('status__id')[:1]
),
current_status=Subquery(
lastest_status.values('status__status')[:1])
)
.values(
'id', 'current_status',
'course_name', 'proposal_url',
'current_status_id'
)
...
@property
def score(self):
scores = self.learning_records.filter(achieved=True) \
.annotate(total_score=Sum("weight__weight")) \
.values_list('total_score', flat=True)
total = sum(list(scores))
core_skill_records = list(
self.core_skills.values_list('level', flat=True))
...
@property
def assessment_overview(self):
for assessment in self.assessments.all().order_by("-assessment__book__index"):
assessment_list.append({
"id": assessment.id,
"name": assessment.assessment.name,
"status": assessment.status.status,
"book": assessment.assessment.assigned_book,
"reviewed_by": assessment.instructor.user.first_name
})
...
@property
def current_cohort(self):
assignment = self.assigned_cohorts.order_by("-id").last()
return {
"name": assignment.cohort.name,
"id": assignment.cohort.id,
"start": assignment.cohort.start_date,
"end": assignment.cohort.end_date,
"courses": assignment.cohort.courses
.order_by('index')
.values('course__name', 'course__id', 'active'),
}
ChatGPT's Disgusting, Useless Response
Combining the operations of the six methods (book, assessment_status, proposals, score, assessment_overview, and current_cohort) into a single Django ORM statement or SQL query to fetch all required information in one go is quite complex and challenging. This is mainly due to the diverse nature of the data these methods retrieve, which spans across different tables with various relationships.
Aha!! Gotcha!!
As soon as I read that, I knew I'd won and proven my superiority. This tool is already admitting that it can't do it. One point for humans.

Wait.... what? Are there yet more foes that need to be vanquished?
However, I can outline an approach to create a more efficient SQL query or a set of queries that could potentially reduce the total execution time. The goal here would be to minimize the number of database hits by fetching related data in bulk and then processing it in Python.
Recommendation: Database Function or Stored Procedure:
Given the complexity, consider implementing a database function or stored procedure that encapsulates this logic within the database. This allows you to maintain complex logic in one place and potentially improve performance by utilizing database-specific optimizations.
After creating the stored procedure, you can call it from Django using a raw SQL query:
from django.db import connection
def get_student_details(user_id):
with connection.cursor() as cursor:
cursor.execute("CALL get_student_details(%s);", [user_id])
result = cursor.fetchone() # or fetchall() based on your needs
return result
PostgreSQL Function for Student Details
This PostgreSQL function aims to provide a comprehensive overview of a student's details, including their latest book project, current cohort, assessment status, and a simplified score calculation. Given the varied nature of the data, some simplifications and assumptions are made for the sake of brevity and clarity.
-- I have removed much of the SQL, also for the
-- sake of brevity of this blog post
CREATE OR REPLACE FUNCTION get_student_details(student_user_id INT)
RETURNS TABLE (
full_name TEXT,
latest_project_name TEXT,
latest_book_name TEXT,
...
) AS $$
BEGIN
RETURN QUERY
WITH student_info AS (
SELECT
au.id,
au.first_name || ' ' || au.last_name AS full_name
FROM auth_user au
WHERE au.id = student_user_id
),
latest_project AS (
SELECT
sp.student_id,
p.name AS project_name,
p.id as project_id,
...
FROM "LearningAPI_studentproject" sp
...
),
current_cohort AS (
SELECT
nuc.nss_user_id,
c.name AS cohort_name,
...
),
assessment_status_agg AS (
SELECT
sa.student_id,
sa.status_id,
...
FROM "LearningAPI_studentassessment" sa
...
),
score_calc AS (
SELECT
lr.student_id,
SUM(lw.weight) AS total_score
FROM "LearningAPI_learningrecord" lr
JOIN ...
)
SELECT
si.full_name,
...
lp.book_id AS latest_book_id,
coalesce(asa.status, 'Not Started') AS assessment_status,
coalesce(sc.total_score, 0) AS total_score
FROM student_info si
LEFT JOIN latest_project lp ON si.id = lp.student_id
...;
END; $$
LANGUAGE plpgsql;
🤔
Stunned Silence
Ok, so I copy that into my SQL file and execute it. Dubious 🤨, but hopeful because my initial scan of the query had me feeling that it looked... kinda right.
I ran it for one student. It was right.
I ran it for another student in a different project. It was right.
I ran it for a student that wasn't working on an assessment. It was right.
I ran it for a student that was working on an assessment. It was right.
I ran it for a student that hadn't submitted a proposal. It was right.
I ran it for a student that had a capstone proposal and it was currently being reviewed. It was right.
I'm not going to lie. I absolutely could have completed all of this work myself using Google and my own knowledge. It also would have taken me a week, multiple dozens of Google searches, myriad mistakes, and multiple versions until I got a working version.
One thing that it missed is that I wanted to get this information for every student in a cohort, so the next step is to modify it for that data. I prompted it to update the query, but it didn't do that great of a job, and I needed to take over and finish it up myself.
I'd Like A Second Opinion
Ok, so ChatGPT did give it a valiant shot and saved me a considerable amount of time, but now my curiosity was piqued. I decided to shop my problem around to other interested parties. I'd heard good things of Claude so I headed down the highway to that shop.
I fed it the exact same prompts with no modifications and I was pleasantly surprised to see that it took a completely different approach. First, it produced an ORM statement that it believed met the requirements. ChatGPT didn't even try.
The ORM Edition
from django.db.models import OuterRef, Subquery, F, Sum
class NssUser(models.Model):
@property
def combined_data(self):
subquery = StudentProject.objects.filter(student=OuterRef('pk')).order_by('-date_created')
return self.prefetch_related('assessments', 'assessments__status', 'capstones', 'learning_records', 'core_skills', 'assigned_cohorts').annotate(
latest_student_project = Subquery(subquery.values('project__book__id')[:1]),
latest_student_project_name = Subquery(subquery.values('project__book__name')[:1]),
latest_student_project_index = Subquery(subquery.values('project__book__index')[:1]),
latest_student_project_date = Subquery(subquery.values('date_created')[:1]),
latest_assessment = Subquery(self.assessments.filter(assessment__book=OuterRef('latest_student_project')).order_by('-date_created').values('status__status')[:1]),
learning_record_score = Subquery(self.learning_records.filter(achieved=True).annotate(total=Sum('weight__weight')).values('total')[:1], output_field=models.IntegerField()),
current_cohort = Subquery(self.assigned_cohorts.order_by('-id').values('cohort__name')[:1])
).values(
'latest_student_project',
'latest_student_project_name',
'latest_assessment',
'learning_record_score',
'current_cohort',
# add other needed fields here
)
The LEFT JOIN Edition
Now that was a great start, but it didn't stop there. It also generated SQL, but instead of using CTEs it just LEFT JOINed the heck out it.
SELECT
nu.user_id,
nu.first_name || ' ' || nu.last_name AS user_name,
sp.project_id AS latest_project_id,
p.name AS latest_project_name,
sa.status AS latest_assessment_status,
lr.total_score AS learning_record_score,
c.name AS current_cohort
FROM LearningAPI_nssuser nu
JOIN LearningAPI_nssusercohort nc
ON nc.nss_user_id = nu.id
JOIN LearningAPI_cohort c
ON c.id = nc.cohort_id
LEFT JOIN LearningAPI_studentproject sp
ON sp.student_id = nu.id AND sp.date_created = (
SELECT MAX(date_created)
FROM LearningAPI_studentproject
WHERE student_id = nu.id
)
LEFT JOIN LearningAPI_project p
ON p.id = sp.project_id
LEFT JOIN LearningAPI_studentassessment sa
ON sa.student_id = nu.id AND sa.date_created = (
SELECT MAX(date_created)
FROM LearningAPI_studentassessment
WHERE student_id = nu.id
)
LEFT JOIN (
SELECT lre.student_id, SUM(lw.weight) AS total_score
FROM LearningAPI_learningrecord lr
JOIN LearningAPI_learningrecordentry lre ON lre.record_id = lr.id
JOIN LearningAPI_learningweight lw ON lw.id = lr.weight_id
WHERE lr.achieved = true
GROUP BY lre.student_id
) lr ON lr.student_id = nu.id
WHERE nc.cohort_id = cohort_id;
Again, that gets me about 90% of where I want to be and saved a lot of mistakes and me stupidly typing in syntax errors and yelling at myself. After tinkering with it for about 10 minutes, I got this version working the way I wanted.
So after all of this, I have two versions of a Postgres function that I can use in my app. Now I can take on the task of actually evaluating their performance in my actual application and make a judgement call on which one to use.
Time to Ask My Copilot
Until I originally published this article, I had never used Github Copilot.
Update on March 1, 2024
I made the assumption that since Copilot is an extension for VS Code that it had the capability of navigating my database structure via the Django models that are right there in the project. Based on that assumption, I provide the more concise prompt below.
Generate a read-only property that uses a direct connection to the database and a SQL statement to get the following information related to NSSUser. The current book the user is assigned to, the status of the current StudentAssessment being worked on (if any), a list of related Capstone rows, the SUM() of the
weightfield on the LearningRecord rows assigned to the user, all of the information from Cohort and CohortInfo for the most recent cohort the user is assigned to, all of the StudentNote records assigned to the user, and all of the Tag records assigned to the user via the StudentTag model. This is to replace all of the existing methods in this model. The generated code should not utilize any existing method or property.
The prompt was specific and provided guidance on exactly what I needed. Unfortunately, it did not produce a very accurate SQL statement. I include it below, but also removed chunks of it for brevity's sake. Because I didn't provide the DBML, it also misspelled some of the table names.
Once again the strategy for the SQL statement is very different from either ChatGPT or Claude. This produced more nested subqueries than the other two, and used some different functions.
SELECT
COALESCE(p.book_id, 0) AS book_id,
COALESCE(p.name, '') AS book_name,
COALESCE(a.status, '') AS assessment_status,
c.id AS cohort_id,
c.name AS cohort_name,
ci.client_course_url,
ci.server_course_url,
ci.zoom_url,
c.start_date,
c.end_date,
ci.student_organization_url,
SUM(lr.weight) AS learning_record_weight_sum,
ARRAY_AGG(DISTINCT sn.id) AS student_note_ids,
ARRAY_AGG(DISTINCT t.id) AS tag_ids
FROM
"LearningAPI_nssuser" AS u
LEFT JOIN (
-- Subquery
WHERE sp.date_created = (
-- Sub subquery
)
) AS p ON u.id = p.student_id
LEFT JOIN (
SELECT *
FROM "LearningAPI_studentassessment" AS sa
INNER JOIN ...
WHERE sa.date_created = (
-- Another sub subquery
)
) AS a ON u.id = a.student_id
LEFT JOIN (
-- More sub queries and sub subqueries
) AS c ON u.id = c.id
LEFT JOIN "LearningAPI_learningrecord" AS lr ON u.id = lr.student_id
LEFT JOIN "LearningAPI_studentnote" AS sn ON u.id = sn.student_id
LEFT JOIN "LearningAPI_studenttag" AS st ON u.id = st.student_id
LEFT JOIN "LearningAPI_tag" AS t ON st.tag_id = t.id
WHERE
u.id = 414
GROUP BY
u.id, p.book_id, etc...
;
The True Power of GenAI
The point of this article was to demonstrate how ridiculously sophisticated these GenAI tools are, and how much time can be saved by software developers... if they learn how to generate powerful prompts and provide the context the tool needs.
As of right now, I find 100x time more value when I ask it to help me improve my code instead of asking it to generate new code from scratch.This saved me a tremendous amount of very complex, and cognitively challenging work, but it didn't do it for me.
It's not like I was working at my desk and it came up behind me like, "Hey dude, it's Gene. I saw you working on this ticket, but it looked cool so I did it for you. Here's the code."
(side note: I didn't like Gene)
- I had to understand the real problem.
- I had to know how to prompt a GenAI for valuable responses.
- I had to have the DBML for my database generated.
- I had to know which model, and which methods on that model were the bad actors.
- I had to design a very comprehensive, and specific, prompt that told it exactly what problem needed to be solved.
- I had to tell it how I wanted it to act and respond to my queries.
- I made sure to verify each solution and provide adjustments 3 times.
I feel pity for the low to mid-value developers on the Web that bash GenAI as a hack or a cheat that only losers use.
It's a new tool with a tremendous amount of power, for good or evil. It has some people (like me) thrilled and excited about the benefits that it brings to the world of software development. Some people are curmudgeons and say how much it sucks, or that it's a crutch for bad software developers.
I get it. Coming from a place of fear and anxiety is pretty normal for humans when confronted with something new like this.
"I learned it {insert some old way} and I turned out just fine! You kids these days want to take the easy way out."
To which I always call bullshit. If this tool was available to any of these folks when they were just starting out, it would have been like a miracle and they all would have used it.